Le métier de web analyste est jonché de multiples obstacles. Parmi ceux-ci, la qualité du tracking est probablement le plus sensible !
Combien d’analyses se sont vus annulées (ou restreintes) suite à un bug tracking ?
Pour contrer cela, il est indispensable de continuellement recetter le dataLayer, les events, les hits et la data dans l’interface Analytics.
En effet, chaque mise en production peut remettre en cause la qualité de votre tracking. Vous imaginez donc aisément le temps passé sur une tâche qui en plus n’est pas toujours très « fun ».
Cela peut représenter une grosse partie du métier de Web Analyste, au détriment de notre réelle valeur ajoutée que sont l’analyse et la préconisation.
Alors, existe-t-il un outil qui permet de solutionner ce problème ? 🙄
La réponse est oui, et il s’appelle Seenaptic ! 😊
Qu’est-ce que Seenaptic ?
Chez ATECNA, nous testons Seenaptic depuis plus d’un an pour l’un de nos clients. Édité par Netvigie, cet outil de recette automatisée s’avère être une réponse parfaitement adaptée aux problématiques énoncées ci-dessus.
Le mode de fonctionnement est simple : L’outil crawle votre site à fréquence régulière (tel un robot qui passerait d’URL en URL) et vérifie que le tracking spécifié par vos soins correspond à ce qu’il a pu collecter sur les différentes pages.
Mais bien entendu, cela nécessite une phase de paramétrage importante !
- Voici les différentes étapes à suivre pour configurer l’outil : d’abord, nous définissons les « contextes », c’est-à-dire les templates de page. C’est comme cela que l’outil comprend par exemple que « une URL = une fiche produit » .
Cela peut se faire de différentes manières :
- Un pattern d’URL contient « /fiche-produit/ »
- Un sélecteur CSS : ma page doit contenir la classe « produit »
- etc…
Ici, notre exemple de la configuration des fiches produit (une regex vérifiant l’URL, puis deux exclusions basées sur le dataLayer) :
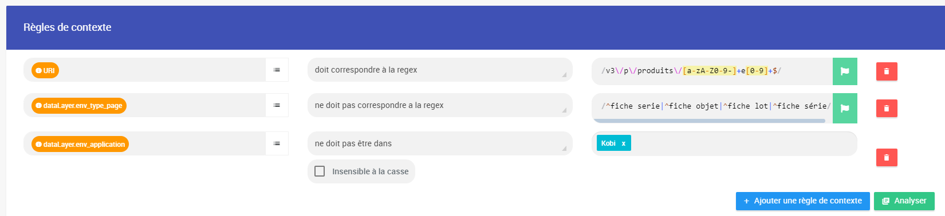
Quand l’outil crawle une URL correspondant à cette règle, il sait désormais que c’est une fiche produit. 👍🏻
- Ensuite, nous définissons nos « collecteurs » : afin de vérifier que le dataLayer est conforme, nous devons avoir un point de comparaison. Or, le meilleur moyen est de trouver l’information correspondante dans la page.
Imaginons que ma variable « product.number_reviews » renvoie le nombre d’avis de mon produit. Je peux créer un collecteur CSS allant chercher le nombre d’avis affiché sur mes fiches produit. Si mon dataLayer me renvoie ‘12’ et que mon collecteur m’indique ‘15’, c’est qu’il y a un bug quelque part.
Autre exemple concret de collecteur, celui qui récupère l’ID du produit sur nos fiches :
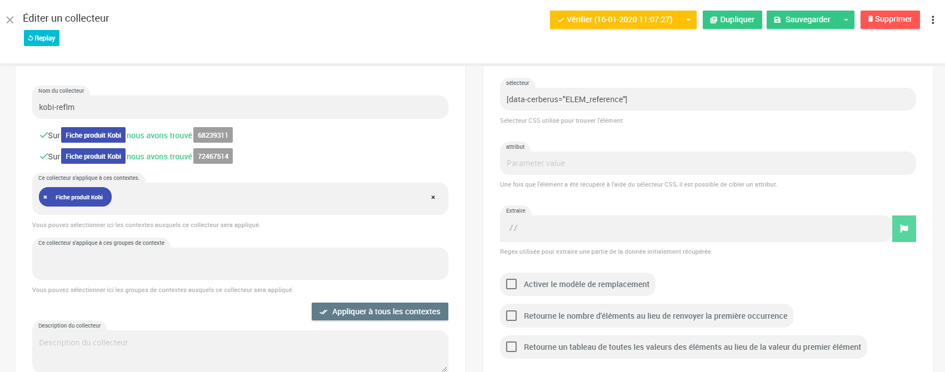
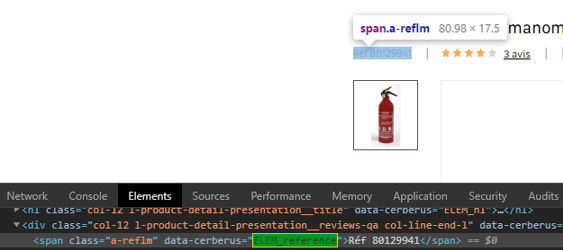
Il va chercher cette information via un sélecteur CSS, dans une data présente dans le code source.
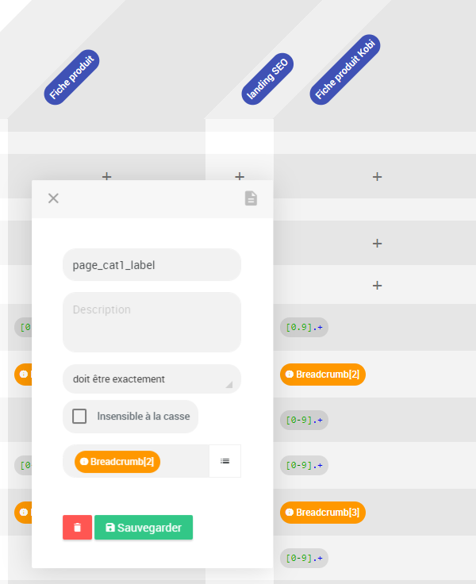
Nous définissons le « plan de marquage », c’est-à-dire les variables dataLayer attendues sur chaque template.
Ici, nous pouvons définir des valeurs fixes, ou dynamiques. Par exemple, nous pouvons définir que, sur nos fiches produit, la variable dataLayer « page_name » doit toujours correspondre au contenu du collecteur H1.
Autre exemple, toujours sur nos fiches produit.
Ici, nous définissons le fait que la variable dataLayer « page_cat1_label » soit égale au deuxième niveau de notre collecteur « fil d’ariane ».
- Et pour finir le paramétrage, nous créons des scénarios afin que l’outil puisse accéder aux pages inaccessibles via le crawl (exemple : page confirmation de commande). Pour cela, nous avons la possibilité de guider le robot dans la réalisation de différentes étapes.
Exemple : se rendre sur une URL Fiche produit > Cliquer sur la classe « ajout panier » > Cliquer sur bouton « vers panier » > Cliquer vers « étape livraison » > Choisir « livraison domicile » > Cliquer vers « étape paiement » > Cliquer sur « chèque » > affichage confirmation commande.
Il est d’ailleurs possible de « forcer » la réalisation d’un scénario avant chaque crawl. Par exemple, vous pouvez paramétrer le scénario d’acceptation des cookies, c’est à dire que le robot va accepter les cookies avant de crawler les pages du site.
La restitution des crawls : scores et alertes
Certes, toute cette phase de paramétrage prend du temps, mais par la suite, le gain de temps sur la recette manuelle est conséquent !
Passons maintenant à la partie la plus intéressante : la lecture des résultats ! 🤩
L’intérêt est que nous obtenons :
- Un score qualité pour chaque crawl.
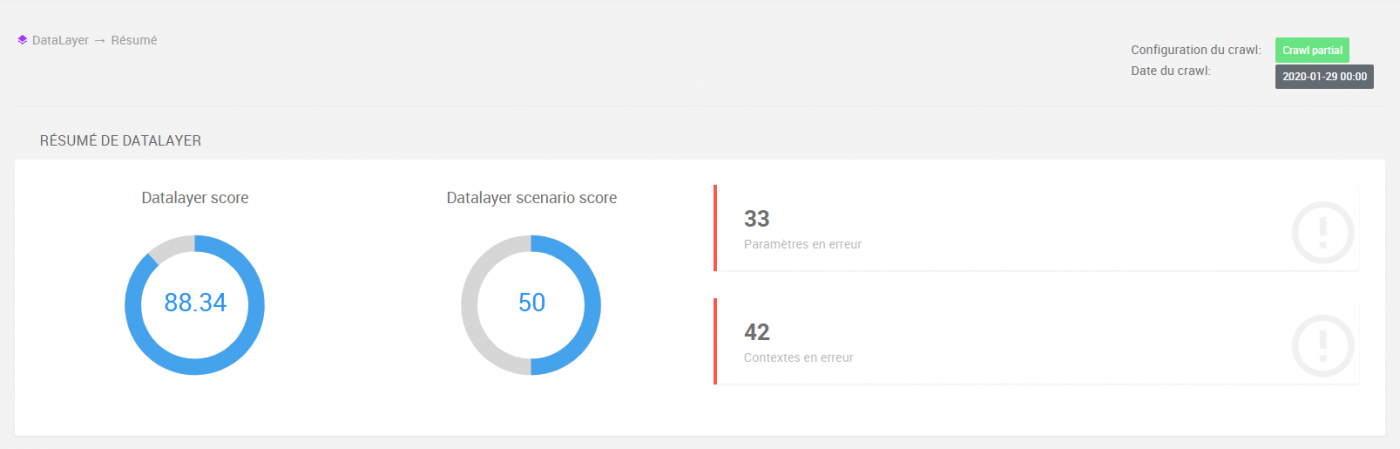
- Un score qualité par variable et par contexte.
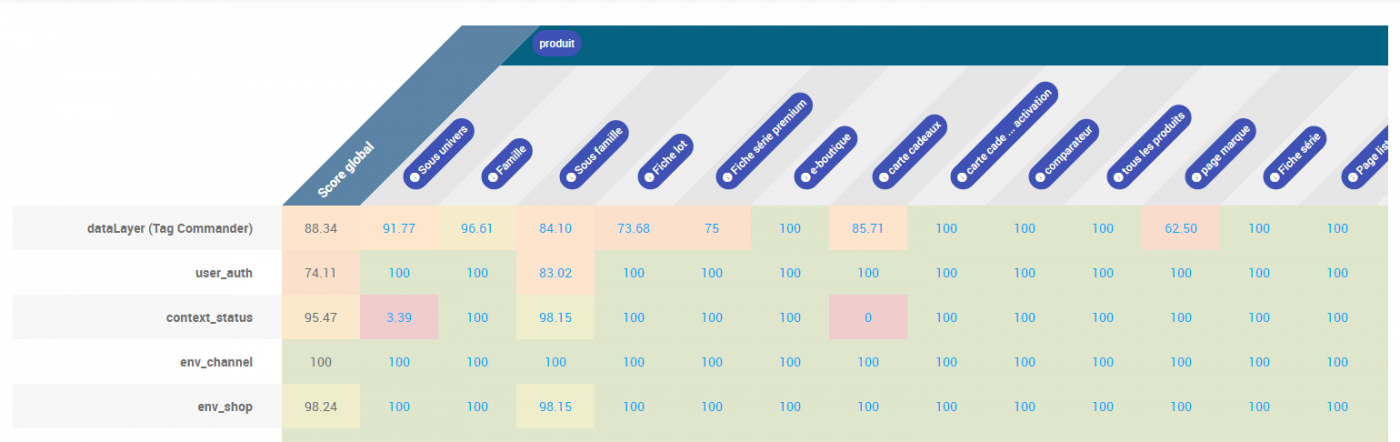
Exemple
Lors du crawl, le robot a trouvé 100 fiches produit.
Parmi celles-ci, 33 n’avaient pas la bonne valeur dans la variable « product.number_reviews ». Le score qualité de cette variable est donc de 77.
C’est ce score qui permet d’obtenir des alertes « intelligentes ». En effet, si le lendemain le score est de 75, c’est une alerte. Par contre, si le score passe à 90, ce n’est plus une alerte. C’est même plus intelligent que cela car il y a une notion de significativité.
Comment recetter les hits vers mon outil Analytics ?
La recette automatisée est également déclinable sur le contenu des hits envoyés à Google Analytics, Adobe Analytics etc.
Pour cela, un autre paramétrage est nécessaire : il faut en effet définir les valeurs attendues dans nos variables Analytics.
Exemple
Sur mes fiches produit, ma custom dim 11 (cd11) doit contenir une suite de chiffres.
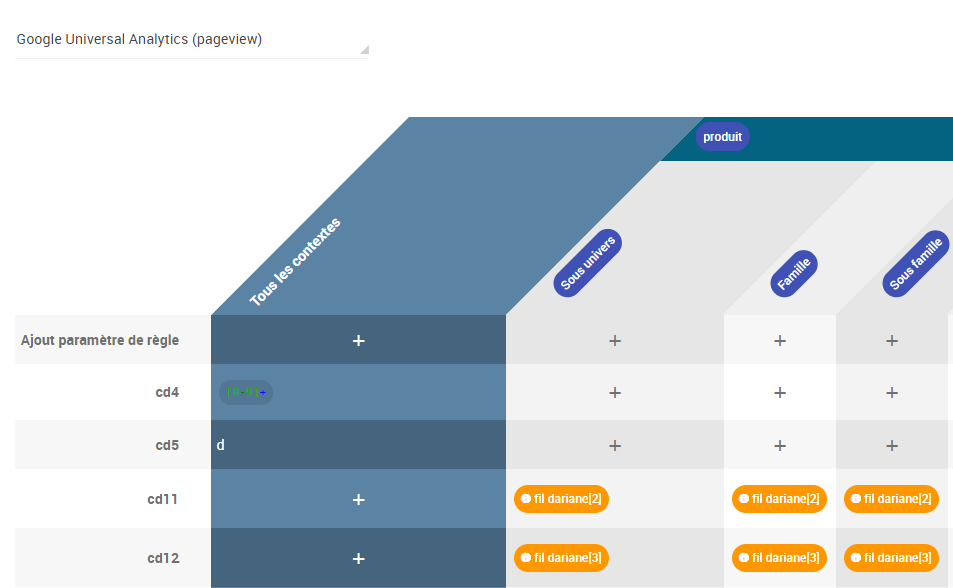
Ceci est possible sur tous les types de tags (Criteo, Facebook, etc…), mais notons tout de même que si le dataLayer est bon, il y a de fortes chances pour que les hits le soient également. 😉
Notre retour d’expérience
ATECNA accompagne un client depuis un peu plus d’un an sur l’implémentation de l’outil, au niveau de la configuration initiale jusqu’à la mise à jour au fil des projets.
Nous testons aujourd’hui les variables dataLayer sur la quasi-totalité des pages du site. Cela a permis à de nombreuse de détecter des bugs en preprod, ainsi que certains en prod. Les premiers lots de recette comprenaient presque une centaine de correctifs. Dans un contexte de replatforming technique, avec plusieurs grosses mises en production par mois (et parfois sans tracking !), Seenaptic représente donc une réelle plus-value.
Nous nous focalisons désormais sur les événements personnalisés, notamment les events e-commerce (impression produit, clic produit, ajout panier …). Ce sont généralement ceux-ci qui sont à la base des reports « phares ».
Next step : la vérification des hits envoyés à Google Analytics.
On apprécie 😍
- Outil paramétrable selon les besoins, pour peu qu’on s’y connaisse un peu en JavaScript et CSS.
- Une équipe à l’écoute des besoins de l’utilisateur, à laquelle il est très facile de faire remonter une demande d’évolution.
- Interface agréable.
- Visualisation claire du détail des erreurs, grâce à une restitution visuelle.
- Une fois configuré « aux petits oignons », le plan de marquage de Seenaptic peut devenir la référence de l’équipe. C’est un moyen sûr de s’assurer que le document est à jour, et de voir si une variable est fiable.
On aimerait voir améliorer 🙄
- Certaines tâches sont répétitives et chronophages (la configuration du plan de marquage notamment). Une fonctionnalité d’export Excel de la configuration actuelle, puis de réimport dans l’interface – une fois modifié dans un tableur – serait un énorme plus.
- La navigation entre les différentes parties de l’outil pourrait être améliorée, sans avoir plusieurs onglets dans le navigateur. On peut se perdre facilement dans le dédale de popins aujourd’hui.
- La mise à disposition de graphiques avec les évolutions dans le temps, afin de pouvoir les présenter par exemple lors de points d’étape ou de rétros.
En résumé, l’outil répond complètement à notre irritant de la qualité de la donnée. Bien qu’assez complexe avec une ergonomie à optimiser, il permet tout de même de monitorer automatiquement la data pour se concentrer davantage sur l’analyse pure et dure.
Si on arrive à y allouer suffisamment de temps, cet outil est un must !